Character Encodings in Perl
This article describes the different character encodings, how they may lead to problems, and how they can be handled in Perl programs.
German and French versions exist too.
Introduction
It happens far too often: a program works fine with latin characters, but it produces weird, unreadable characters as soon as it has to process other characters like Chinese or Japanese characters or modified latin characters like the German Umlauts Ä, Ö etc. or the Scandinavian characters å and Ø.
ASCII
To understand the root of the problem you have to understand how "normal" Latin characters and other characters (the ones that cause problems) are stored.
It all began in the year 1963 with ASCII, the "American Standard for Information Interchange". It maps 128 characters to the number from 0 to 127, which can be encoded with 7 bits.
Since a byte contains 8 bits, the first, "most significant" bit in ASCII characters is always zero.
The standard defines the Latin letters a to z in
both upper and lower case, the Arabic digits 0 to
9, whitespace like "blank" and "carriage return", a few
control characters and a few special signs like %,
$ and so on.
Characters that aren't essential in the day to day life of an American citizen are not defined in ASCII, like Cyrillic letters, "decorated" Latin characters, Greek characters and so on.
Other Character Encodings
When people started to use computers in other countries, other characters needed to be encoded. In the European countries ASCII was reused, and the 128 unused numbers per byte were used for the locally needed characters.
In Western Europe the character encoding was called "Latin 1", and later standardized as ISO-8859-1. Latin 2 was used in central Europe and so on.
In each of the Latin-* charsets the first 128 characters are identical to ASCII, so they can be viewed as ASCII extensions. The second 128 byte values are each mapped to characters needed in the regions where these character sets were used.
In other parts of world other character encodings were developed, like EUC-CN in China and Shift-JIS in Japan.
These local charsets are very limited. When the Euro was introduced in 2001, many European countries had a currencies whose symbols couldn't be expressed in the traditional character encodings.
Unicode
The charsets mentioned so far can encode only a small part of all possible characters, which makes it nearly impossible to create documents that contain letters from different scripts.
In an attempt to unify all scripts into a single writing system, the Unicode consortium was created, and it started to collect all known characters, and assign a unique number to each, called a "codepoint".
The codepoint is usually written as a four or six digit hex number, like
U+0041. The corresponding name is LATIN SMALL LETTER A.
Apart from letters and other "base characters", there are also accents
and decorations like ACCENT, COMBINING ACUTE, which can be
added to a base character.
If a base char is followed by one or more of these marking characters, this compound forms a logical character called "grapheme".
Note that many pre-composed graphemes exist for characters that are defined in other character sets, and these pre-composed are typically better supported by current software than the equivalent written as base character and combining mark.
Unicode Transformation Formats
The concept of Unicode codepoints and graphemes is completely independent of the encoding.
There are different ways to encode these codepoints, and these mappings from codepoints to bytes are called "Unicode Transformation Formats". The most well known is UTF-8, which is a byte based format that uses all possible byte values from 0 to 255. In Perl land there is also a lax version called UTF8 (without the hyphen). The Perl module Encode distinguishes these versions.
Windows uses mostly UTF-16 which uses at least two bytes per codepoint,
for very high codepoints it uses 4 bytes. There are two variants of
UTF-16, which are marked with the suffix LE for "little
endian" and -BE for "big endian" (see Endianess).
UTF-32 encodes every codepoint in 4 bytes. It is the only fixed width encoding that can implement the whole Unicode range.
| Codepoint | Char | ASCII | UTF-8 | Latin-1 | ISO-8859-15 | UTF-16 |
|---|---|---|---|---|---|---|
| U+0041 | A | 0x41 | 0x41 | 0x41 | 0x41 | 0x00 0x41 |
| U+00c4 | Ä | - | 0xc3 0x84 | 0xc4 | 0xc4 | 0x00 0xc4 |
| U+20AC | € | - | 0xe3 0x82 0xac | - | 0xa4 | 0x20 0xac |
| U+c218 | 수 | - | 0xec 0x88 0x98 | - | - | 0xc2 0x18 |
(The letter in the last line is the Hangul syllable SU, and your browser will only display it correctly if you have the appropriate Asian fonts installed.)
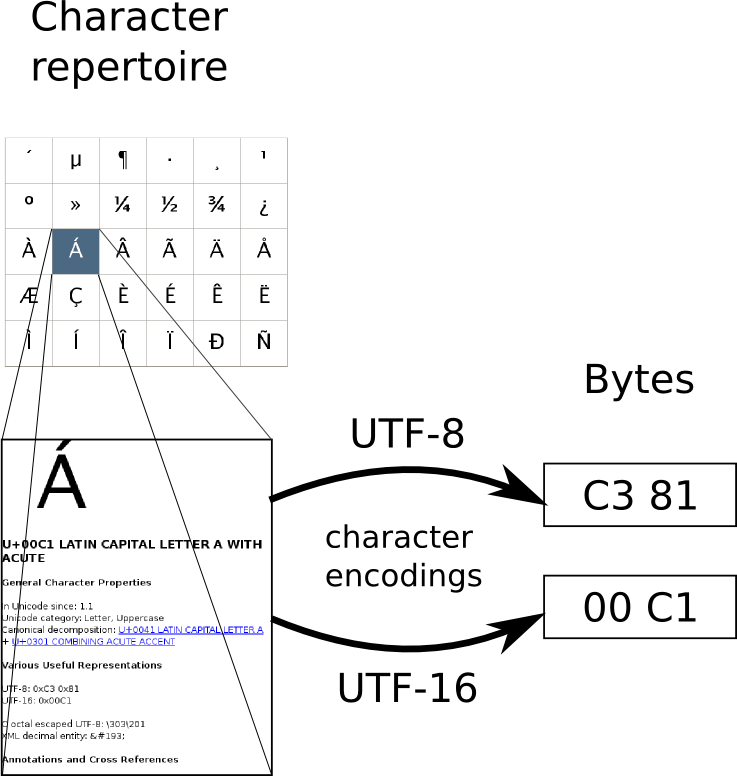
Unicode defines a character repertoire of codepoints and their properties.
Character encodings like UTF-8 and UTF-16 define a way to write them as a
short sequence of bytes.
Perl 5 and Character Encodings
Perl Strings can either be used to hold text strings or binary data. Given a string, you generally have no mechanism of finding out whether it holds text or binary data - you have to keep track of it yourself.
Interaction with the environment (like reading data from
STDIN or a file, or printing it) treats strings as binary
data.
The same holds true for the return value of many built-in functions (like
gethostbyname) and special variables that
carry information to your program (%ENV and @ARGV).
Other builtin functions that deal with text (like uc
and lc and regular expressions) treat strings as text,
or more accurately as a list of
Codepoints.
With the function decode in the module Encode you decode binary
strings to make sure that the text handling functions work correctly.
All text operations should work on strings that have been decoded by
Encode::decode (or in other ways described below).
Otherwise the text processing functions assume that the string is stored
as Latin-1, which will yield incorrect results for any other encoding.
Note that cmp only compares non-ASCII chars by codepoint
number, which might give unexpected results. In general the ordering
is language dependent, so that you need use locale in effect to
sort strings according the rules of a natural language. For example, in
German the desired ordering is 'a' lt 'ä' and 'ä' lt 'b',
whereas comparison by codepoint number gives 'ä' gt 'b'.
#!/usr/bin/perl use warnings; use strict; use Encode qw(encode decode); my $enc = 'utf-8'; # This script is stored as UTF-8 my $str = "Ä\n"; # Byte strings: print lc $str; # prints 'Ä', lc didn't have any effect # text strings:: my $text_str = decode($enc, $byte_str); $text_str = lc $text_str; print encode($enc, $text_str); # prints 'ä', lc worked as expected
It is highly recommended to convert all input to text strings, then work with the text strings, and only covert them back to byte strings on output or storing.
Otherwise, you can get confused very fast, and lose track of which strings are byte strings, and which ones are text strings.
Perl offers IO layers, which are easy mechanisms to make these conversions automatically, either globally or per file handle.
# IO layer: $handle now decodes all strings upon reading open my $handle, '<:encoding(UTF-8)', $file; # same open my $handle, '<', $datei; binmode $handle, ':encoding(UTF-8)'; # each open() automatically uses :encoding(iso-8859-1) use open ':encoding(iso-8859-1)'; # All string literals in the script are interpreted as text strings: use utf8; # (assumes the script to be stored in UTF-8 # Get the current locale from the environment, and let STDOUT # convert to that encoding: use PerlIO::locale; binmode STDOUT, ':locale'; # all I/O with current locale: use open ':locale';
Care should be taken with the input layer :utf8, which often
pops up in example code and old documentation: it assumes
the input to be in valid UTF-8, and you have no way of knowing in your
program if that was actually the case.
If not, it's a source of
subtle security holes, see
this article on
perlmonks.org for details. Don't ever use it as an input layer,
use :encoding(UTF-8) instead.
The module and pragma utf8 also allows you to use non-ASCII
chars in variable names and module names. But beware, don't do this for
package and module names; it might not work well.
Also, consider that not everybody has a keyboard that allows easy typing of
non-ASCII characters, so you make maintenance of your code much harder if
you use them in your code.
Testing your Environment
You can use the following short script to your terminal, locales and fonts. It is very European centric, but you should be able to modify it to use the character encodings that are normally used where you live.
#!/usr/bin/perl use warnings; use strict; use Encode; my @charsets = qw(utf-8 latin1 iso-8859-15 utf-16); # some non-ASCII codepoints: my $test = 'Ue: ' . chr(220) .'; Euro: '. chr(8364) . "\n"; for (@charsets){ print "$_: " . encode($_, $test); }
If you run this program in a terminal, only one line will be displayed correctly, and its first column is the character encoding of your terminal.
The Euro sign € isn't in Latin-1, so if your terminal has that
encoding, the Euro sign won't be displayed correctly.
Windows terminals mostly use cp* encodings, for example
cp850 or cp858 (only available in new versions
of Encode) for German windows installations. The rest of the operating
environment uses Windows-* encodings, for example
Windows-1252 for a number of Western European localizations.
Encode->encodings(":all"); returns a list of
all available encodings.
Troubleshooting
"Wide Character in print"
Sometimes you might see the Wide character in print warning.
This means that you tried to use decoded string data in a context where it
only makes sense to have binary data, in this case printing it. You can
make the warning go away by using an appropriate output layer, or by
piping the offending string through Encode::encode first.
Inspecting Strings
Sometimes you want to inspect if a string from an unknown source has already been decoded. Since Perl has no separate data types for binary strings and decoded strings, you can't do that reliably.
But there is a way to guess the answer by using the module Devel::Peek
use Devel::Peek; use Encode; my $str = "ä"; Dump $str; $str = decode("utf-8", $str); Dump $str; Dump encode('latin1', $str); __END__ SV = PV(0x814fb00) at 0x814f678 REFCNT = 1 FLAGS = (PADBUSY,PADMY,POK,pPOK) PV = 0x81654f8 "\303\244"\0 CUR = 2 LEN = 4 SV = PV(0x814fb00) at 0x814f678 REFCNT = 1 FLAGS = (PADBUSY,PADMY,POK,pPOK,UTF8) PV = 0x817fcf8 "\303\244"\0 [UTF8 "\x{e4}"] CUR = 2 LEN = 4 SV = PV(0x814fb00) at 0x81b7f94 REFCNT = 1 FLAGS = (TEMP,POK,pPOK) PV = 0x8203868 "\344"\0 CUR = 1 LEN = 4
The string UTF8 in the line starting with FLAGS
= shows that the string has been decoded already.
The line starting with PV = holds the bytes, and in brackets
the codepoints.
But there is a big caveat: Just because the UTF8 flag isn't present
doesn't mean that the text string hasn't been decoded. Perl uses either
Latin-1 or UTF-8 internally to store strings, and the presence of this
flag indicates which one is used.
That also implies that if your program is written in Perl only (and has no XS components) it is almost certainly an error to rely on the presence or absence of that flag. You shouldn't care how perl stores its strings anyway.
Buggy Modules
A common source of errors are buggy modules. The pragma
encoding looks very tempting:
# automatic conversion to and from the current locale use encoding ':locale';
But under the effect of use encoding, some AUTOLOAD
functions stop working, and the module isn't thread safe.
Character Encodings in the WWW
When you write a CGI script you have to chose a character encoding, print all your data in that encoding, and write it in the HTTP headers.
For most applications, UTF-8 is a good choice, since you can code arbitrary Unicode codepoints with it. On the other hand English text (and of most other European languages) is encoded very efficiently.
HTTP offers the Accept-Charset-Header in which the client can
tell the server which character encodings it can handle. But if you stick
to the common encodings like UTF-8 or Latin-1, next to all user agents
will understand it, so it isn't really necessary to check that header.
HTTP headers themselves are strictly ASCII only, so all information that is sent in the HTTP header (including cookies and URLs) need to be encoded to ASCII if non-ASCII characters are used.
For HTML files the header typically looks like this:
Content-Type: text/html; charset=UTF-8. If you send such a
header, you only have to escape those characters that have a special
meaninig in HTML: <, >, &
and, in attributes, ".
Special care must be taken when reading POST or GET parameters with the
function param in the module CGI. Older
versions (prior to 3.29) always returned byte strings, newer version
return text strings if charset("UTF-8") has been called
before, and byte strings otherwise.
CGI.pm also doesn't support character encodings other than UTF-8.
Therefore you should not to use the charset routine
and explicitly decode the parameter strings yourself.
To ensure that form contents in the browser are sent with a known charset,
you can add the accept-charset attribute to the
<form> tag.
<form method="post" accept-charset="utf-8" action="/script.pl">
If you use a template system, you should take care to choose one that
knows how to handle character encodings. Good examples are
Template::Alloy,
HTML::Template::Compiled
(since version 0.90 with the open_mode option), or
Template Toolkit (with the ENCODING option in the constructor
and an IO layer in the process method).
Modules
There are a plethora of Perl modules out there that handle text, so here are only a few notable ones, and what you have to do to make them Unicode-aware:
LWP::UserAgent and WWW::Mechanize
Use the $response->decode_content instead of just
$response->content. That way the character encoding
information sent in the HTTP response header is used to decode the
body of the response.
DBI
DBI leaves handling of character encodings to the DBD:: (driver) modules, so what you have to do depends on which database backend you are using. What most of them have in common is that UTF-8 is better supported than other encodings.
For Mysql and DBD::mysql
pass the mysql_enable_utf8 => 1 option to the
DBI->connect call.
For Postgresql and DBD::Pg, set the
pg_enable_utf8 attribute to 1
For SQLite and DBD::SQLite, set the
sqlite_unicode attribute to 1
Advanced Topics
With the basic charset and Perl knowledge you can get quite far. For example, you can make a web application "Unicode safe", i.e. you can take care that all possible user inputs are displayed correctly, in any script the user happens to use.
But that's not all there is to know on the topic. For example, the Unicode standard allows different ways to compose some characters, so you need to "normalize" them before you can compare two strings. You can read more about that in the Unicode normalization FAQ.
To implement country specific behaviour in programs, you should take a
look at the locales system. For example in Turkey lc 'I', the
lower case of the capital letter I is ı, U+0131 LATIN SMALL LETTER
DOTLESS I, while the upper case of i is İ,
U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE.
A good place to start reading about locales is perldoc
perllocale.
Philosophy
Many programmers who are confronted with encoding issues first react with "But shouldn't it just work?". Yes, it should just work. But too many systems are broken by design regarding character sets and encodings.
Broken by Design
"Broken by Design" most of the time means that a document format, and API or a protocol allows multiple encodings, without a normative way on how that encoding information is transported and stored out of band.
A classical example is the Internet Relay Chat (IRC), which specifies that a character is one Byte, but not which character encoding is used. This worked well in the Latin-1 days, but was bound to fail as soon as people from different continents started to use it.
Currently, many IRC clients try to autodetect character encodings, and recode it to what the user configured. This works quite well in some cases, but produces really ugly results where it doesn't work.
Another Example: XML
The Extensible Markup Language, commonly known by its abbreviation XML, lets you specific the character encoding inside the file:
<?xml version="1.0" encoding="UTF-8" ?>
There are two reasons why this is insufficient:
- The encoding information is optional. The specification clearly states that the encoding must be UTF-8 if the encoding information is absent, but sadly many tool authors don't seem to know that, end emit Latin-1. (This is of course only partly the fault of the specification).
- Any XML parser first has to autodetect the encoding to be able to parse the encoding information
The second point is really important. You'd guess "Ah, that's no problem, the preamble is just ASCII" - but many encodings are ASCII-incompatible in the first 127 bytes (for example UTF-7, UCS-2 and UTF-16).
So although the encoding information is available, the parser first has to guess nearly correctly to extract it.
The appendix to the XML specification contains a detection algorithm than can handle all common cases, but for example lacks UTF-7 support.
How to Do it Right: Out-of-band Signaling
The XML example above demonstrates that a file format can't carry encoding information in the file itself, unless you specify a way to carry that encoding information on the byte level, independently of the encoding of the rest of the file.
A possible workaround could have been to specific that the first line of any XML file has to be ASCII encoded, and the rest of the file is in the encoding that is specified in that first line. But it's an ugly workaround: a normal text editor would display the first line completely wrong if the file is in an ASCII-incompatible encoding. Of course it's also incompatible with current XML specification, and would require a new, incompatible specification, which would in turn break all existing applications.
So how to do it right, then?
The answer is quite simple: Every system that works with text data has to either store meta data separately, or store everything in a uniform encoding.
It is tempting to store everything in the same encoding, and it works quite well on a local machine, but you can't expect everyone to agree on one single encoding, so all data exchange still has to carry encoding information. And usually you want to store original files (for fear of data loss), so you have to keep that encoding information somewhere.
This observation should have a huge impact on the computing world: all file systems should allow you to store encoding information as meta data, and easily retrieve that meta data. The same should hold true for file names, and programming languages (at least those who want to take the pain away from their users) should transparently transport that meta information, and take care of all encoding issues.
Then it could just work.
Further reading
- W3c tutorial on character encodings in HTML and CSS
- Perl Programming/Unicode UTF-8 wikibook
- perlunitut, the Perl Unicode Tutorial
Useful Tools
- gucharmap, the Gnome Unicode character map.
- An UTF-8 dumper that shows you the name of non-ASCII characters.
-
hexdump
never lies (on Debian it's in the
bsdmainutilspackage). - iconv converts text files from one character encoding to another.
Acknowledgments
This article is a translation of a German article of mine written for $foo-Magazin 01/2008, a German Perl magazine. It was enhanced and corrected since then.
Many thanks go to Juerd Waalboer, who pointed out many smaller and a few not-so-small errors in earlier versions of this article, and contributed greatly to my understanding of Perl's string handling.
I'd also like to thank ELISHEVA for suggesting many improvements to both grammar and spelling.
I'd like to acknowledge insightful discussions with: