Categories
Posts in this category
- Automating Deployments: A New Year and a Plan
- Automating Deployments: Why bother?
- Automating Deployments: Simplistic Deployment with Git and Bash
- Automating Deployments: Building Debian Packages
- Automating Deployments: Debian Packaging for an Example Project
- Automating Deployments: Distributing Debian Packages with Aptly
- Automating Deployments: Installing Packages
- Automating Deployments: 3+ Environments
- Architecture of a Deployment System
- Introducing Go Continuous Delivery
- Technology for automating deployments: the agony of choice
- Automating Deployments: New Website, Community
- Continuous Delivery for Libraries?
- Managing State in a Continuous Delivery Pipeline
- Automating Deployments: Building in the Pipeline
- Automating Deployments: Version Recycling Considered Harmful
- Automating Deployments: Stage 2: Uploading
- Automating Deployments: Installation in the Pipeline
- Automating Deployments: Pipeline Templates in GoCD
- Automatically Deploying Specific Versions
- Story Time: Rollbacks Saved the Day
- Automated Deployments: Unit Testing
- Automating Deployments: Smoke Testing and Rolling Upgrades
- Automating Deployments and Configuration Management
- Ansible: A Primer
- Continuous Delivery and Security
- Continuous Delivery on your Laptop
- Moritz on Continuous Discussions (#c9d9)
- Git Flow vs. Continuous Delivery
Sun, 24 Jan 2016
Architecture of a Deployment System
Permanent link
An automated build and deployment system is structured as a pipeline.
A new commit or branch in a version control system triggers the instantiation of the pipeline, and starts executing the first of a series of stages. When a stage succeeds, it triggers the next one. If it fails, the entire pipeline instance stops.
Then manual intervention is necessary, typically by adding a new commit that fixes code or tests, or by fixing things with the environment or the pipeline configuration. A new instance of the pipeline then has a chance to succeed.
Deviations from the strict pipeline model are possible: branches, potentially executed in parallel, for example allow running different tests in different environments, and waiting with the next step until both are completed successfully.

The typical stages are building, running the unit tests, deployment to a first test environment, running integration tests there, potentially deployment to and tests in various test environments, and finally deployment to production.
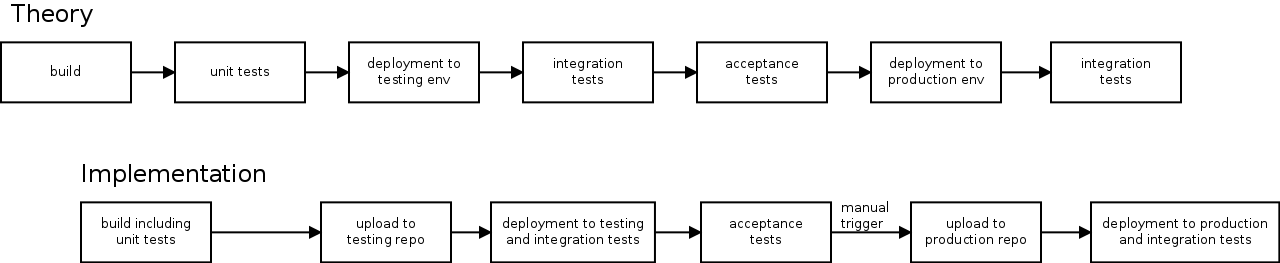
Sometimes, these stages blur a bit. For example, a typical build of Debian packages also runs the unit tests, which alleviates the need for a separate unit testing stage. Likewise if the deployment to an environment runs integration tests for each host it deploys to, there is no need for a separate integration test stage.
Typically there is a piece of software that controls the flow of the whole pipeline. It prepares the environment for a stage, runs the code associated with the stage, collects its output and artifacts (that is, files that the stage produces and that are worth keeping, like binaries or test output), determines whether the stage was successful, and then proceeds to the next.
From an architectural standpoint, it relieves the stages of having to know what stage comes next, and even how to reach the machine on which it runs. So it decouples the stages.
Anti-Pattern: Separate Builds per Environment
If you use a branch model like git
flow for your source
code, it is tempting to automatically deploy the develop branch to the
testing environment, and then make releases, merge them into the master
branch, and deploy that to the production environment.
It is tempting because it is a straight-forward extension of an existing, proven workflow.
Don't do it.
The big problem with this approach is that you don't actually test what's going to be deployed, and on the flip side, deploy something untested to production. Even if you have a staging environment before deploying to production, you are invalidating all the testing you did the testing environment if you don't actually ship the binary or package that you tested there.
If you build "testing" and "release" packages from different sources (like different branches), the resulting binaries will differ. Even if you use the exact same source, building twice is still a bad idea, because many builds aren't reproducible. Non-deterministic compiler behavior, differences in environments and dependencies all can lead to packages that worked fine in one build, and failed in another.
It is best to avoid such potential differences and errors by deploying to production exactly the same build that you tested in the testing environment.
Differences in behavior between the environments, where they are desirable, should be implemented by configuration that is not part of the build. (It should be self-evident that the configuration should still be under version control, and also automatically deployed. There are tools that specialize in deploying configuration, like Puppet, Chef and Ansible.)
I'm writing a book on automating deployments. If this topic interests you, please sign up for the Automating Deployments newsletter. It will keep you informed about automating and continuous deployments. It also helps me to gauge interest in this project, and your feedback can shape the course it takes.