Categories
Posts in this category
- Automating Deployments: A New Year and a Plan
- Automating Deployments: Why bother?
- Automating Deployments: Simplistic Deployment with Git and Bash
- Automating Deployments: Building Debian Packages
- Automating Deployments: Debian Packaging for an Example Project
- Automating Deployments: Distributing Debian Packages with Aptly
- Automating Deployments: Installing Packages
- Automating Deployments: 3+ Environments
- Architecture of a Deployment System
- Introducing Go Continuous Delivery
- Technology for automating deployments: the agony of choice
- Automating Deployments: New Website, Community
- Continuous Delivery for Libraries?
- Managing State in a Continuous Delivery Pipeline
- Automating Deployments: Building in the Pipeline
- Automating Deployments: Version Recycling Considered Harmful
- Automating Deployments: Stage 2: Uploading
- Automating Deployments: Installation in the Pipeline
- Automating Deployments: Pipeline Templates in GoCD
- Automatically Deploying Specific Versions
- Story Time: Rollbacks Saved the Day
- Automated Deployments: Unit Testing
- Automating Deployments: Smoke Testing and Rolling Upgrades
- Automating Deployments and Configuration Management
- Ansible: A Primer
- Continuous Delivery and Security
- Continuous Delivery on your Laptop
- Moritz on Continuous Discussions (#c9d9)
- Git Flow vs. Continuous Delivery
Sun, 24 Apr 2016
Automating Deployments: Building in the Pipeline
Permanent link
The first step of an automated deployment system is always the build. (For a software that doesn't need a build to be tested, the test might come first, but stay with me nonetheless).
At this point, I assume that there is already a build system in place that produces packages in the desired format, here .deb files. Here I will talk about integrating this build step into a pipeline that automatically polls new versions from a git repository, runs the build, and records the resulting .deb package as a build artifact.
A GoCD Build Pipeline
As mentioned earlier, my tool of choice of controlling the pipeline is Go Continuous Delivery. Once you have it installed and configured an agent, you can start to create a pipeline.
GoCD lets you build pipelines in its web interface, which is great for exploring the available options. But for a blog entry, it's easier to look at the resulting XML configuration, which you can also enter directly ("Admin" → "Config XML").
So without further ado, here's the first draft:
<pipelines group="deployment"> <pipeline name="package-info"> <materials> <git url="https://github.com/moritz/package-info.git" dest="package-info" /> </materials> <stage name="build" cleanWorkingDir="true"> <jobs> <job name="build-deb" timeout="5"> <tasks> <exec command="/bin/bash" workingdir="package-info"> <arg>-c</arg> <arg>debuild -b -us -uc</arg> </exec> </tasks> <artifacts> <artifact src="package-info*_*" dest="package-info/" /> </artifacts> </job> </jobs> </stage> </pipeline> </pipelines>
The outer-most group is a pipeline group, which has a name. It can be used to make it easier to get an overview of available pipelines, and also to manage permissions. Not very interesting for now.
The second level is the <pipeline> with a name, and it contains a list of
materials and one or more stages.
Materials
A material is anything that can trigger a pipeline, and/or provide files that commands in a pipeline can work with. Here the only material is a git repository, which GoCD happily polls for us. When it detects a new commit, it triggers the first stage in the pipeline.
Directory Layout
Each time a job within a stage is run, the go agent (think worker) which runs
it prepares a directory in which it makes the materials available. On linux,
this directory defaults to /var/lib/go-agent/pipelines/$pipline_name.
Paths in the GoCD configuration are typically relative to this path.
For example the material definition above contains the attribute
dest="package-info", so the absolute path to this git repository is
/var/lib/go-agent/pipelines/package-info/package-info. Leaving out the
dest="..." works, and gives on less level of directory, but only works for a
single material. It is a rather shaky assumption that you won't need a second
material, so don't do that.
See the config references for a list of available material types and options. Plugins are available that add further material types.
Stages
All the stages in a pipeline run serially, and each one only if the previous stage succeed. A stage has a name, which is used both in the front end, and for fetching artifacts.
In the example above, I gave the stage the attribute
cleanWorkingDir="true", which makes GoCD delete files created during the
previous build, and discard changes to files under version control. This tends
to be a good option to use, otherwise you might unknowingly slide into a
situation where a previous build affects the current build, which can be
really painful to debug.
Jobs, Tasks and Artifacts
Jobs are potentially executed in parallel within a stage, and have names for the same reasons that stages do.
Inside a job there can be one or more tasks. Tasks are executed serially
within a job. I tend to mostly use <exec> tasks (and <fetchartifact>,
which I will cover in a later blog post), which invoke system commands. They
follow the UNIX convention of treating an exit status of zero as success, and
everything else as a failure.
For more complex commands, I create shell or Perl scripts inside a git repository, and add repository as a material to the pipeline, which makes them available during the build process with no extra effort.
The <exec> task in our example invokes /bin/bash -c 'debuild -b -us -uc'.
Which is a case of Cargo Cult
Programming, because
invoking debuild directly works just as well. Ah well, will revise later.
debuild -b -us -uc builds the Debian package, and is executed inside the git
checkout of the source. It produces a .deb file, a .changes file and possibly
a few other files with meta data. They are created one level above the git
checkout, so in the root directory of the pipeline run.
These are the files that we want to work with later on, we let GoCD store them
in an internal database. That's what the <artifact> instructs GoCD to do.
Since the name of the generated files depends on the version number of the
built Debian package (which comes from the debian/changelog file in the git
repo), it's not easy to reference them by name later on. That's where the
dest="package-info/" comes in play: it makes GoCD store the artifacts in a
directory with a fixed name. Later stages then can retrieve all artifact files
from this directory by the fixed name.
The Pipeline in Action
If nothing goes wrong (and nothing ever does, right?), this is roughly what the web interface looks like after running the new pipeline:
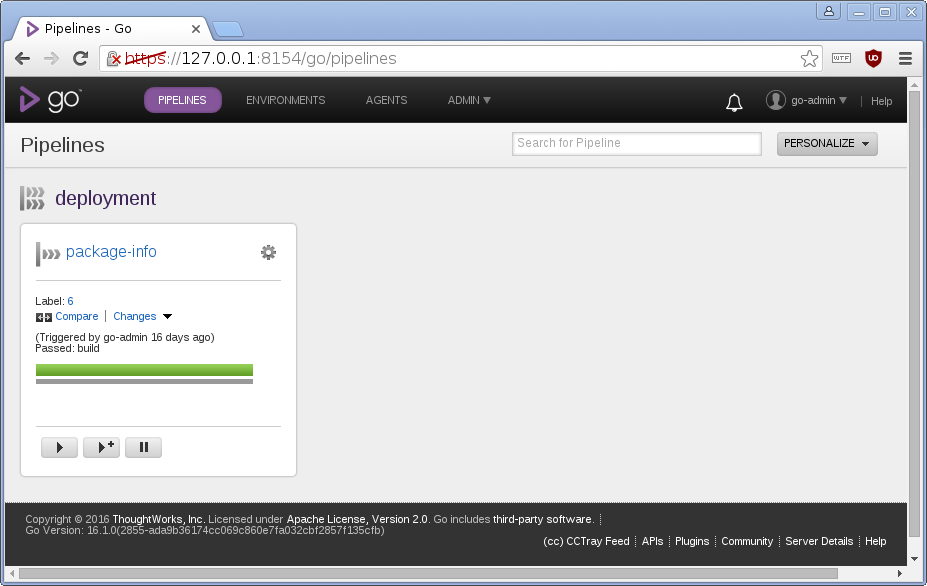
So, whenever there is a new commit in the git repository, GoCD happily builds a Debian pacckage and stores it for further use. Automated builds, yay!
But there is a slight snag: It recycles version numbers, which other Debian tools are very unhappy about. In the next blog post, I'll discuss a way to deal with that.
I'm writing a book on automating deployments. If this topic interests you, please sign up for the Automating Deployments newsletter. It will keep you informed about automating and continuous deployments. It also helps me to gauge interest in this project, and your feedback can shape the course it takes.