Categories
Posts in this category
- Automating Deployments: A New Year and a Plan
- Automating Deployments: Why bother?
- Automating Deployments: Simplistic Deployment with Git and Bash
- Automating Deployments: Building Debian Packages
- Automating Deployments: Debian Packaging for an Example Project
- Automating Deployments: Distributing Debian Packages with Aptly
- Automating Deployments: Installing Packages
- Automating Deployments: 3+ Environments
- Architecture of a Deployment System
- Introducing Go Continuous Delivery
- Technology for automating deployments: the agony of choice
- Automating Deployments: New Website, Community
- Continuous Delivery for Libraries?
- Managing State in a Continuous Delivery Pipeline
- Automating Deployments: Building in the Pipeline
- Automating Deployments: Version Recycling Considered Harmful
- Automating Deployments: Stage 2: Uploading
- Automating Deployments: Installation in the Pipeline
- Automating Deployments: Pipeline Templates in GoCD
- Automatically Deploying Specific Versions
- Story Time: Rollbacks Saved the Day
- Automated Deployments: Unit Testing
- Automating Deployments: Smoke Testing and Rolling Upgrades
- Automating Deployments and Configuration Management
- Ansible: A Primer
- Continuous Delivery and Security
- Continuous Delivery on your Laptop
- Moritz on Continuous Discussions (#c9d9)
- Git Flow vs. Continuous Delivery
Sat, 14 May 2016
Automatically Deploying Specific Versions
Permanent link
Versions. Always talking about versions. So, more talk about versions.
The installation pipeline from a previous installment always installs the newest version available. In a normal, simple, linear development flow, this is fine, and even in other workflows, it's a good first step.
But we really want the pipeline to deploy the exact versions that was built inside the same instance of the pipeline. The obvious benefit is that it allows you to rerun older versions of the pipeline to install older versions, effectively giving you a rollback.
Or you can build a second pipeline for hotfixes, based on the same git repository but a different branch, and when you do want a hotfix, you simply pause the regular pipeline, and trigger the hotfix pipeline. In this scenario, if you always installed the newest version, finding a proper version string for the hotfix is nearly impossible, because it needs to be higher than the currently installed one, but also lower than the next regular build. Oh, and all of that automatically please.
A less obvious benefit to installing a very specific version is that it detects error in the package source configuration of the target machines. If the deployment script just installs the newest version that's available, and through an error the repository isn't configured on the target machine, the installation process becomes a silent no-op if the package is already installed in an older version.
Implementation
There are two things to do: figure out version to install of the package, and and then do it.
The latter step is fairly easy, because the ansible "apt" module that I use for installation supports, and even has an example in the documentation:
# Install the version '1.00' of package "foo"
- apt: name=foo=1.00 state=present
Experimenting with this feature shows that in case this is a downgrade, you
also need to add force=yes.
Knowing the version number to install also has a simple, though maybe not obvious solution: write the version number to a file, collect this file as an artifact in GoCD, and then when it's time to install, fetch the artifact, and read the version number from it.
When I last talked about the build
step,
I silently introduced configuration that collects the version file that the
debian-autobuild
script
writes:
<job name="build-deb" timeout="5">
<tasks>
<exec command="../deployment-utils/debian-autobuild" workingdir="#{package}" />
</tasks>
<artifacts>
<artifact src="version" />
<artifact src="package-info*_*" dest="package-info/" />
</artifacts>
</job>
So only the actual installation step needs adjusting. This is what the configuration looked like:
<job name="deploy-testing">
<tasks>
<exec command="ansible" workingdir="deployment-utils/ansible/">
<arg>--sudo</arg>
<arg>--inventory-file=testing</arg>
<arg>web</arg>
<arg>-m</arg>
<arg>apt</arg>
<arg>-a</arg>
<arg>name=package-info state=latest update_cache=yes</arg>
<runif status="passed" />
</exec>
</tasks>
</job>
So, first fetch the version file:
<job name="deploy-testing">
<tasks>
<fetchartifact pipeline="" stage="build" job="build-deb" srcfile="version" />
...
Then, how to get the version from the file to ansible? One could either use
ansible's lookup('file',
path) function, or
write a small script. I decided to the latter, since I was originally more
aware of bash's capabilities than of ansible's, and it's only a one-liner
anyway:
...
<exec command="/bin/bash" workingdir="deployment-utils/ansible/">
<arg>-c</arg>
<arg>ansible --sudo --inventory-file=testing #{target} -m apt -a "name=#{package}=$(< ../../version) state=present update_cache=yes force=yes"</arg>
</exec>
</tasks>
</job>
Bash's $(...) opens a sub-process (which again is a bash instance), and
inserts the output from that sub-process into the command line. <
../../version is a short way of reading the file. And, this being XML, the
less-than sign needs to be escaped.
The production deployment configuration looks pretty much the same, just with
--inventory-file=production.
Try it!
To test the version-specific package installation, you need to have at least
two runs of the pipeline that captured the version artifact. If you don't
have that yet, you can push commits to the source repository, and GoCD picks
them up automatically.
You can query the installed version on the target machine with
dpkg -l package-info. After the last run, the version built in that pipeline
instance should be installed.
Then you can rerun the deployment stage from a previous pipeline, for example in the history view of the pipeline by hovering with the mouse over the stage, and then clicking on the circle with the arrow on it that triggers the rerun.
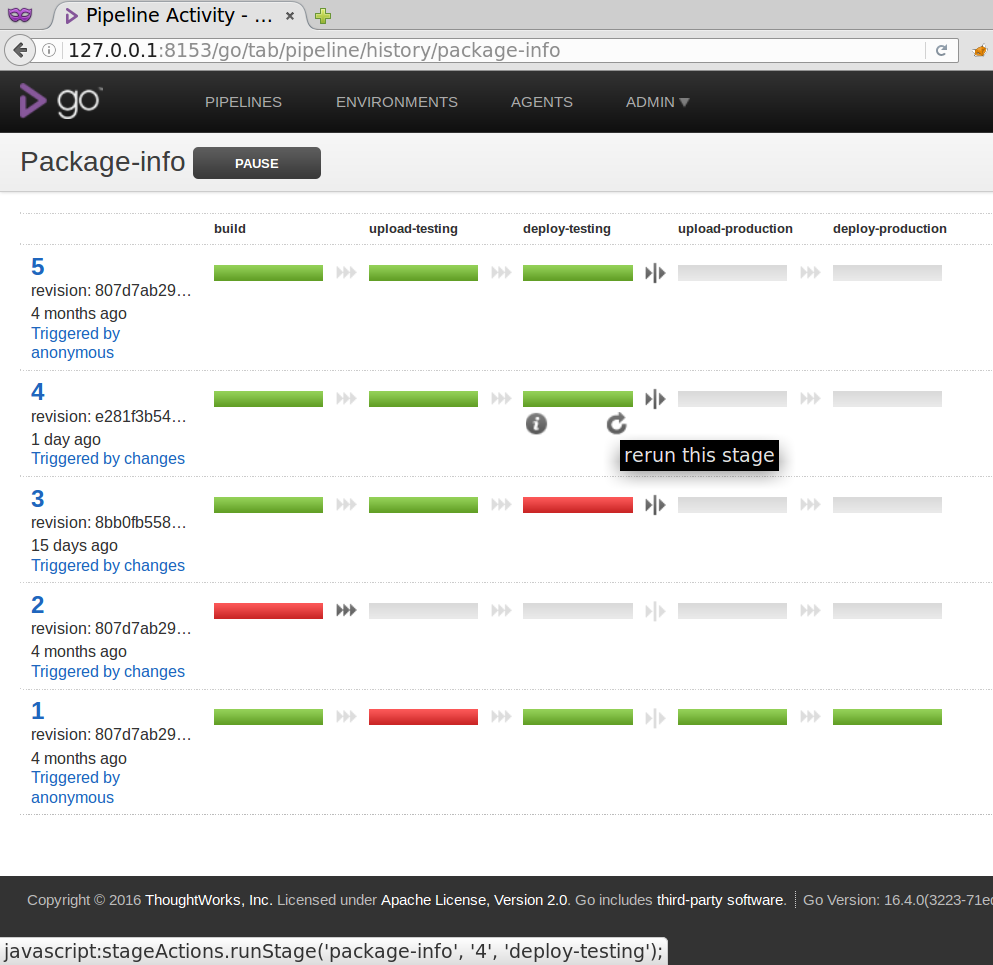
After the stage rerun has completed, checking the installed version again should yield the version built in the pipeline instance that you selected.
Conclusions
Once you know how to set up your pipeline to deploy exactly the version that was built in the same pipeline instance, it is fairly easy to implement.
Once you've done that, you can easily deploy older versions of your software as a step back scenario, and use the same mechanism to automatically build and deploy hotfixes.
I'm writing a book on automating deployments. If this topic interests you, please sign up for the Automating Deployments newsletter. It will keep you informed about automating and continuous deployments. It also helps me to gauge interest in this project, and your feedback can shape the course it takes.