Categories
Posts in this category
- Automating Deployments: A New Year and a Plan
- Automating Deployments: Why bother?
- Automating Deployments: Simplistic Deployment with Git and Bash
- Automating Deployments: Building Debian Packages
- Automating Deployments: Debian Packaging for an Example Project
- Automating Deployments: Distributing Debian Packages with Aptly
- Automating Deployments: Installing Packages
- Automating Deployments: 3+ Environments
- Architecture of a Deployment System
- Introducing Go Continuous Delivery
- Technology for automating deployments: the agony of choice
- Automating Deployments: New Website, Community
- Continuous Delivery for Libraries?
- Managing State in a Continuous Delivery Pipeline
- Automating Deployments: Building in the Pipeline
- Automating Deployments: Version Recycling Considered Harmful
- Automating Deployments: Stage 2: Uploading
- Automating Deployments: Installation in the Pipeline
- Automating Deployments: Pipeline Templates in GoCD
- Automatically Deploying Specific Versions
- Story Time: Rollbacks Saved the Day
- Automated Deployments: Unit Testing
- Automating Deployments: Smoke Testing and Rolling Upgrades
- Automating Deployments and Configuration Management
- Ansible: A Primer
- Continuous Delivery and Security
- Continuous Delivery on your Laptop
- Moritz on Continuous Discussions (#c9d9)
- Git Flow vs. Continuous Delivery
Sun, 13 Mar 2016
Continuous Delivery for Libraries?
Permanent link
Past Thursday I gave a talk on Continuous Delivery (slides) at the German Perl Workshop 2016 (video recordings have been made, but aren't available yet). One of the questions from the audience was something along the lines of: would I use Continuous Delivery for a software library?
My take on this is that you typically develop a library driven by the needs of one or more applications, not just for the sake of developing a library. So you have some kind of pilot application which makes use of the new library features.
You can integrate the library into the application's build pipeline. Automatically build and unit test the library, and once it succeeds, upload the library into a repository. The build pipeline for the application can then download the newest version of the library, and include it in its build result (fat-packaging). The application build step now has two triggers: commits from its own version control repository, and library uploads.
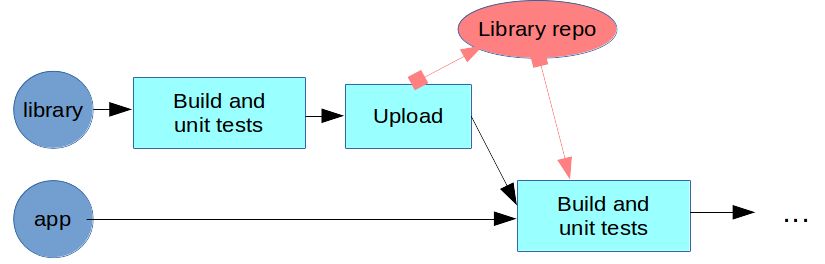
Then the rest of the delivery pipeline for the application serves as quality gating for the library as well. If the pipeline includes integration tests and functional tests for the whole software stack, it will catch errors of the library, and deploy the library along with the application.
I'm writing a book on automating deployments. If this topic interests you, please sign up for the Automating Deployments newsletter. It will keep you informed about automating and continuous deployments. It also helps me to gauge interest in this project, and your feedback can shape the course it takes.