Categories
Posts in this category
- Current State of Exceptions in Rakudo and Perl 6
- Meet DBIish, a Perl 6 Database Interface
- doc.perl6.org and p6doc
- Exceptions Grant Report for May 2012
- Exceptions Grant Report -- Final update
- Perl 6 Hackathon in Oslo: Be Prepared!
- Localization for Exception Messages
- News in the Rakudo 2012.05 release
- News in the Rakudo 2012.06 release
- Perl 6 Hackathon in Oslo: Report From The First Day
- Perl 6 Hackathon in Oslo: Report From The Second Day
- Quo Vadis Perl?
- Rakudo Hack: Dynamic Export Lists
- SQLite support for DBIish
- Stop The Rewrites!
- Upcoming Perl 6 Hackathon in Oslo, Norway
- A small regex optimization for NQP and Rakudo
- Pattern Matching and Unpacking
- Rakudo's Abstract Syntax Tree
- The REPL trick
- First day at YAPC::Europe 2013 in Kiev
- YAPC Europe 2013 Day 2
- YAPC Europe 2013 Day 3
- A new Perl 6 community server - call for funding
- New Perl 6 community server now live, accepting signups
- A new Perl 6 community server - update
- All Perl 6 modules in a box
- doc.perl6.org: some stats, future directions
- Profiling Perl 6 code on IRC
- Why is it hard to write a compiler for Perl 6?
- Writing docs helps you take the user's perspective
- Perl 6 Advent Calendar 2016 -- Call for Authors
- Perl 6 By Example: Running Rakudo
- Perl 6 By Example: Formatting a Sudoku Puzzle
- Perl 6 By Example: Testing the Say Function
- Perl 6 By Example: Testing the Timestamp Converter
- Perl 6 By Example: Datetime Conversion for the Command Line
- What is Perl 6?
- Perl 6 By Example, Another Perl 6 Book
- Perl 6 By Example: Silent Cron, a Cron Wrapper
- Perl 6 By Example: Testing Silent Cron
- Perl 6 By Example: Stateful Silent Cron
- Perl 6 By Example: Perl 6 Review
- Perl 6 By Example: Parsing INI files
- Perl 6 By Example: Improved INI Parsing with Grammars
- Perl 6 By Example: Generating Good Parse Errors from a Parser
- Perl 6 By Example: A File and Directory Usage Graph
- Perl 6 By Example: Functional Refactorings for Directory Visualization Code
- Perl 6 By Example: A Unicode Search Tool
- What's a Variable, Exactly?
- Perl 6 By Example: Plotting using Matplotlib and Inline::Python
- Perl 6 By Example: Stacked Plots with Matplotlib
- Perl 6 By Example: Idiomatic Use of Inline::Python
- Perl 6 By Example: Now "Perl 6 Fundamentals"
- Perl 6 Books Landscape in June 2017
- Living on the (b)leading edge
- The Loss of Name and Orientation
- Perl 6 Fundamentals Now Available for Purchase
- My Ten Years of Perl 6
- Perl 6 Coding Contest 2019: Seeking Task Makers
- A shiny perl6.org site
- Creating an entry point for newcomers
- An offer for software developers: free IRC logging
- Sprixel, a 6 compiler powered by JavaScript
- Announcing try.rakudo.org, an interactive Perl 6 shell in your browser
- Another perl6.org iteration
- Blackjack and Perl 6
- Why I commit Crud to the Perl 6 Test Suite
- This Week's Contribution to Perl 6 Week 5: Implement Str.trans
- This Week's Contribution to Perl 6
- This Week's Contribution to Perl 6 Week 8: Implement $*ARGFILES for Rakudo
- This Week's Contribution to Perl 6 Week 6: Improve Book markup
- This Week's Contribution to Perl 6 Week 2: Fix up a test
- This Week's Contribution to Perl 6 Week 9: Implement Hash.pick for Rakudo
- This Week's Contribution to Perl 6 Week 11: Improve an error message for Hyper Operators
- This Week's Contribution to Perl 6 - Lottery Intermission
- This Week's Contribution to Perl 6 Week 3: Write supporting code for the MAIN sub
- This Week's Contribution to Perl 6 Week 1: A website for proto
- This Week's Contribution to Perl 6 Week 4: Implement :samecase for .subst
- This Week's Contribution to Perl 6 Week 10: Implement samespace for Rakudo
- This Week's Contribution to Perl 6 Week 7: Implement try.rakudo.org
- What is the "Cool" class in Perl 6?
- Report from the Perl 6 Hackathon in Copenhagen
- Custom operators in Rakudo
- A Perl 6 Date Module
- Defined Behaviour with Undefined Values
- Dissecting the "Starry obfu"
- The case for distributed version control systems
- Perl 6: Failing Softly with Unthrown Exceptions
- Perl 6 Compiler Feature Matrix
- The first Perl 6 module on CPAN
- A Foray into Perl 5 land
- Gabor: Keep going
- First Grant Report: Structured Error Messages
- Second Grant Report: Structured Error Messages
- Third Grant Report: Structured Error Messages
- Fourth Grant Report: Structured Error Messages
- Google Summer of Code Mentor Recap
- How core is core?
- How fast is Rakudo's "nom" branch?
- Building a Huffman Tree With Rakudo
- Immutable Sigils and Context
- Is Perl 6 really Perl?
- Mini-Challenge: Write Your Prisoner's Dilemma Strategy
- List.classify
- Longest Palindrome by Regex
- Perl 6: Lost in Wonderland
- Lots of momentum in the Perl 6 community
- Monetize Perl 6?
- Musings on Rakudo's spectest chart
- My first executable from Perl 6
- My first YAPC - YAPC::EU 2010 in Pisa
- Trying to implement new operators - failed
- Programming Languages Are Not Zero Sum
- Perl 6 notes from February 2011
- Notes from the YAPC::EU 2010 Rakudo hackathon
- Let's build an object
- Perl 6 is optimized for fun
- How to get a parse tree for a Perl 6 Program
- Pascal's Triangle in Perl 6
- Perl 6 in 2009
- Perl 6 in 2010
- Perl 6 in 2011 - A Retrospection
- Perl 6 ticket life cycle
- The Perl Survey and Perl 6
- The Perl 6 Advent Calendar
- Perl 6 Questions on Perlmonks
- Physical modeling with Math::Model and Perl 6
- How to Plot a Segment of a Circle with SVG
- Results from the Prisoner's Dilemma Challenge
- Protected Attributes Make No Sense
- Publicity for Perl 6
- PVC - Perl 6 Vocabulary Coach
- Fixing Rakudo Memory Leaks
- Rakudo architectural overview
- Rakudo Rocks
- Rakudo "star" announced
- My personal "I want a PONIE" wish list for Rakudo Star
- Rakudo's rough edges
- Rats and other pets
- The Real World Strikes Back - or why you shouldn't forbid stuff just because you think it's wrong
- Releasing Rakudo made easy
- Set Phasers to Stun!
- Starry Perl 6 obfu
- Recent Perl 6 Developments August 2008
- The State of Regex Modifiers in Rakudo
- Strings and Buffers
- Subroutines vs. Methods - Differences and Commonalities
- A SVG plotting adventure
- A Syntax Highlighter for Perl 6
- Test Suite Reorganization: How to move tests
- The Happiness of Design Convergence
- Thoughts on masak's Perl 6 Coding Contest
- The Three-Fold Function of the Smart Match Operator
- Perl 6 Tidings from September and October 2008
- Perl 6 Tidings for November 2008
- Perl 6 Tidings from December 2008
- Perl 6 Tidings from January 2009
- Perl 6 Tidings from February 2009
- Perl 6 Tidings from March 2009
- Perl 6 Tidings from April 2009
- Perl 6 Tidings from May 2009
- Perl 6 Tidings from May 2009 (second iteration)
- Perl 6 Tidings from June 2009
- Perl 6 Tidings from August 2009
- Perl 6 Tidings from October 2009
- Timeline for a syntax change in Perl 6
- Visualizing match trees
- Want to write shiny SVG graphics with Perl 6? Port Scruffy!
- We write a Perl 6 book for you
- When we reach 100% we did something wrong
- Where Rakudo Lives Now
- Why Rakudo needs NQP
- Why was the Perl 6 Advent Calendar such a Success?
- What you can write in Perl 6 today
- Why you don't need the Y combinator in Perl 6
- You are good enough!
Sun, 19 Aug 2012
Quo Vadis Perl?
Permanent link
The last two days we had a gathering in town named Perl (yes, a place with that name exists). It's a lovely little town next to the borders to France and Luxembourg, and our meeting was titled "Perl Reunification Summit".
Sadly I only managed to arrive in Perl on Friday late in the night, so I missed the first day. Still it was totally worth it.
We tried to answer the question of how to make the Perl 5 and the Perl 6 community converge on a social level. While we haven't found the one true answer to that, we did find that discussing the future together, both on a technical and on a social level, already brought us closer together.
It was quite a touching moment when Merijn "Tux" Brand explained that he was skeptic of Perl 6 before the summit, and now sees it as the future.
We also concluded that copying API design is a good way to converge on a technical level. For example Perl 6's IO subsystem is in desperate need of a cohesive design. However none of the Perl 6 specification and the Rakudo development team has much experience in that area, and copying from successful Perl 5 modules is a viable approach here. Path::Class and IO::All (excluding the crazy parts) were mentioned as targets worth looking at.
There is now also an IRC channel to continue our discussions -- join
#p6p5 on irc.perl.org if you are interested.
We also discussed ways to bring parallel programming to both perls. I missed most of the discussion, but did hear that one approach is to make easier to send other processes some serialized objects, and thus distribute work among several cores.
Patrick Michaud gave a short ad-hoc presentation on implicit parallelism in Perl 6. There are several constructs where the language allows parallel execution, for example for Hyper operators, junctions and feeds (think of feeds as UNIX pipes, but ones that allow passing of objects and not just strings). Rakudo doesn't implement any of them in parallel right now, because the Parrot Virtual Machine does not provide the necessary primitives yet.
Besides the "official" program, everybody used the time in meat space to discuss their favorite projects with everybody else. For example I took some time to discuss the future of doc.perl6.org with Patrick and Gabor Szabgab, and the relation to perl6maven with the latter. The Rakudo team (which was nearly completely present) also discussed several topics, and I was happy to talk about the relation between Rakudo and Parrot with Reini Urban.
Prior to the summit my expectations were quite vague. That's why it's hard for me to tell if we achieved what we and the organizers wanted. Time will tell, and we want to summarize the result in six to nine months. But I am certain that many participants have changed some of their views in positive ways, and left the summit with a warm, fuzzy feeling.
I am very grateful to have been invited to such a meeting, and enjoyed it greatly. Our host and organizers, Liz and Wendy, took care of all of our needs -- travel, food, drinks, space, wifi, accommodation, more food, entertainment, food for thought, you name it. Thank you very much!
Update: Follow the #p6p5 hash tag on twitter if you want to read more, I'm sure other participants will blog too.
Other blogs posts on this topic: PRS2012 – Perl5-Perl6 Reunification Summit by mdk and post-yapc by theorbtwo
Tue, 17 Jul 2012
Stop The Rewrites!
Permanent link
What follows is a rant. If you're not in the mood to read a rant right now, please stop and come back in an hour or two.
The Internet is full of people who know better than you how to manage your open source project, even if they only know some bits and pieces about it. News at 11.
But there is one particular instance of that advice that I hear often applied to Rakudo Perl 6: Stop the rewrites.
To be honest, I can fully understand the sentiment behind that advice. People see that it has taken us several years to get where we are now, and in their opinion, that's too long. And now we shouldn't waste our time with rewrites, but get the darn thing running already!
But Software development simply doesn't work that way. Especially not if your target is moving, as is Perl 6. (Ok, Perl 6 isn't moving that much anymore, but there are still areas we don't understand very well, so our current understanding of Perl 6 is a moving target).
At some point or another, you realize that with your current design, you can only pile workaround on top of workaround, and hope that the whole thing never collapses.

Image courtesy of sermoa
Those people who spread the good advice to never do any major rewrites again, they never address what you should do when you face such a situation. Build the tower of workarounds even higher, and pray to Cthulhu that you can build it robust enough to support a whole stack of third-party modules?
Curiously this piece of advice occasionally comes from people who otherwise know a thing or two about software development methodology.
I should also add that since the famous "nom" switchover, which admittedly caused lots of fallout, we had three major rewrites of subsystems (longest-token matching of alternative, bounded serialization and qbootstrap), All three of which caused no new test failures, and two of which caused no fallout from the module ecosystem at all. In return, we have much faster startup (factor 3 to 4 faster) and a much more correct regex engine.
Wed, 04 Jul 2012
doc.perl6.org and p6doc
Permanent link
Background
Earlier this year I tried to assess the readiness of the Perl 6 language, compilers, modules, documentation and so on. While I never got around to publish my findings, one thing was painfully obvious: there is a huge gap in the area of documentation.
There are quite a few resources, but none of them comprehensive (most comprehensive are the synopsis, but they are not meant for the end user), and no single location we can point people to.
Announcement
So, in the spirit of xkcd, I
present yet another incomplete documentation project:
doc.perl6.org and p6doc.
The idea is to take the same approach as perldoc for Perl 5: create user-level documentation in Pod format (here the Perl 6 Pod), and make it available both on a website and via a command line tool. The source (documentation, command line tool, HTML generator) lives at https://github.com/perl6/doc/. The website is doc.perl6.org.
Oh, and the last Rakudo Star release (2012.06) already shipped p6doc.
Status and Plans
Documentation, website and command line tool are all in very early stages of development.
In the future, I want both
p6doc SOMETHING and
http://doc.perl6.org/SOMETHING to either document or link to
documentation of SOMETHING, be it a built-in variable, an operator, a
type name, routine name, phaser, constant or... all the other possible
constructs that occur in Perl 6. URLs and command line arguments
specific to each type of construct will also be available
(/type/SOMETHING URLs already work).
Finally I want some way to get a "full" view of a type, ie providing all methods from superclasses and roles too.
Help Wanted
All of that is going to be a lot of work, though the most work will be to write the documentation. You too can help! You can write new documentation, gather and incorporate already existing documentation with compatible licenses (for example synopsis, perl 6 advent calendar, examples from rosettacode), add more examples, proof-read the documentation or improve the HTML generation or the command line tool.
If you have any questions about contributing, feel free to ask in #perl6. Of course you can also; create pull requests right away :-).
Fri, 22 Jun 2012
News in the Rakudo 2012.06 release
Permanent link
Rakudo development continues to progress nicely, and so there are a few changes in this month's release worth explaining.
Longest Token Matching, List Iteration
The largest chunk of development effort went into Longest-Token Matching for alternations in Regexes, about which Jonathan already blogged. Another significant piece was Patrick's refactor of list iteration. You probably won't notice much of that, except that for-loops are now a bit faster (maybe 10%), and laziness works more reliably in a couple of cases.
String to Number Conversion
String to number conversion is now stricter than before. Previously an
expression like +"foo" would simply return 0. Now it fails, ie
returns an unthrown exception. If you treat that unthrown exception like a
normal value, it blows up with a helpful error message, saying that the
conversion to a number has failed. If that's not what you want, you can still
write +$str // 0.
require With Argument Lists
require now supports argument lists, and that needs a bit more
explaining. In Perl 6 routines are by default only looked up in lexical
scopes, and lexical scopes are immutable at run time. So, when loading a
module at run time, how do you make functions available to the code that loads
the module? Well, you determine at compile time which symbols you want to
import, and then do the actual importing at run time:
use v6; require Test <&plan &ok &is>; # ^^^^^^^^^^^^^^^ evaluated at compile time, # declares symbols &plan, &ok and &is # ^^^ loaded at run time
Module Load Debugging
Rakudo had some trouble when modules were precompiled, but its dependencies were not. This happens more often than it sounds, because Rakudo checks timestamps of the involved files, and loads the source version if it is newer than the compiled file. Since many file operations (including simple copying) change the time stamp, that could happen very easily.
To make debugging of such errors easier, you can set the
RAKUDO_MODULE_DEBUG environment variable to 1 (or any positive
number; currently there is only one debugging level, in the future higher
numbers might lead to more output).
$ RAKUDO_MODULE_DEBUG=1 ./perl6 -Ilib t/spec/S11-modules/require.t MODULE_DEBUG: loading blib/Perl6/BOOTSTRAP.pbc MODULE_DEBUG: done loading blib/Perl6/BOOTSTRAP.pbc MODULE_DEBUG: loading lib/Test.pir MODULE_DEBUG: done loading lib/Test.pir 1..5 MODULE_DEBUG: loading t/spec/packages/Fancy/Utilities.pm MODULE_DEBUG: done loading t/spec/packages/Fancy/Utilities.pm ok 1 - can load Fancy::Utilities at run time ok 2 - can call our-sub from required module MODULE_DEBUG: loading t/spec/packages/A.pm MODULE_DEBUG: loading t/spec/packages/B.pm MODULE_DEBUG: loading t/spec/packages/B/Grammar.pm MODULE_DEBUG: done loading t/spec/packages/B/Grammar.pm MODULE_DEBUG: done loading t/spec/packages/B.pm MODULE_DEBUG: done loading t/spec/packages/A.pm ok 3 - can require with variable name ok 4 - can call subroutines in a module by name ok 5 - require with import list
Module Loading Traces in Compile-Time Errors
If module myA loads module myB, and myB dies during compilation, you now get a backtrace which indicates through which path the erroneous module was loaded:
$ ./perl6 -Ilib -e 'use myA' ===SORRY!=== Placeholder variable $^x may not be used here because the surrounding block takes no signature at lib/myB.pm:1 from module myA (lib/myA.pm:3) from -e:1
Improved autovivification
Perl allows you to treat not-yet-existing array and hash elements as arrays or hashes, and automatically creates those elements for you. This is called autovivification.
my %h; %h<x>.push: 1, 2, 3; # worked in the previous release too push %h<y>, 4, 5, 6; # newly works in the 2012.06
Thu, 07 Jun 2012
Localization for Exception Messages
Permanent link
Ok, my previous blog post wasn't quite as final as I thought.. My exceptions grant said that the design should make it easy to enable localization and internationalization hooks. I want to discuss some possible approaches and thereby demonstrate that the design is flexible enough as it is.
At this point I'd like to mention that much of the flexibility comes from either Perl 6 itself, or from the separation of stringifying and exception and generating the actual error message.
Mixins: the sledgehammer
One can always override a method in an object by mixing in a role which
contains the method on question. When the user requests error messages in a
different language, one can replace method Str or method
message with one that generates the error message in a different
language.
Where should that happen? The code throws exceptions is fairly scattered over the code base, but there is a central piece of code in Rakudo that turns Parrot-level exceptions into Perl 6 level exceptions. That would be an obvious place to muck with exceptions, but it would mean that exceptions that are created but not thrown don't get the localization. I suspect that's a fairly small problem in the real world, but it still carries code smell. As does the whole idea of overriding methods.
Another sledgehammer: alternative setting
Perl 6 provides built-in types and routines in an outer lexical scope known as a "setting". The default setting is called CORE. Due to the lexical nature of almost all lookups in Perl 6, one can "override" almost anything by providing a symbol of the same name in a lexical scope.
One way to use that for localization is to add another setting between the
user's code and CORE. For example a file DE.setting:
my class X::Signature::Placeholder does X::Comp { method message() { 'Platzhaltervariablen können keine bestehenden Signaturen überschreiben'; } }
After compiling, we can load the setting:
$ ./perl6 --target=pir --output=DE.setting.pir DE.setting
$ ./install/bin/parrot -o DE.setting.pbc DE.setting.pir
$ ./perl6 --setting=DE -e 'sub f() { $^x }'
===SORRY!===
Platzhaltervariablen können keine bestehenden Signaturen überschreiben
at -e:1
That works beautifully for exceptions that the compiler throws, because they look up exception types in the scope where the error occurs. Exceptions from within the setting are a different beast, they'd need special lookup rules (though the setting throws far fewer exceptions than the compiler, so that's probably manageable).
But while this looks quite simple, it comes with a problem: if a module is
precompiled without the custom setting, and it contains a reference to an
exception type, and then the l10n setting redefines it, other programs will
contain references to a different class with the same name. Which means that
our precompiled module might only catch the English version of
X::Signature::Placeholder, and lets our localized exception pass
through. Oops.
Tailored solutions
A better approach is probably to simply hack up the string conversion in
type Exception to consider a translator routine if present, and
pass the invocant to that routine. The translator routine can look up the
error message keyed by the type of the exception, and has access to all data
carried in the exception. In untested Perl 6 code, this might look like
this:
# required change in CORE my class Exception { multi method Str(Exception:D:) { return self.message unless defined $*LANG; if %*TRANSLATIONS{$*LANG}{self.^name} -> $translator { return $translator(self); } return self.message; # fallback } } # that's what a translator could write: %*TRANSLATIONS<de><X::TypeCheck::Assignment> = { "Typenfehler bei Zuweisung zu '$_.symbol()': " ~ "'{$_.expected.^name}' erwartet, aber '{$_.got.^name} bekommen" } }
And setting the dynamic language $*LANG to 'de'
would give a German error message for type check failures in assignment.
Another approach is to augment existing error classes and add methods that
generate the error message in different languages, for example method
message-fr for French, and check their existence in
Exception.Str if a different language is requested.
Conclusion
In conclusion there are many bad and enough good approaches; we will decide which one to take when the need arises (ie when people actually start to translate error messages).
Tue, 05 Jun 2012
Exceptions Grant Report -- Final update
Permanent link
In my previous blog post I mentioned that I'm nearly done with my exceptions Hague grant. I have since done all the things that I identified as still missing.
In particular I ack
through the setting for remaining uses of die, and the only thing
left are internal errors, error messages about not-yet-implemented things and
the actual declaration of die. Which means that everything that
should be a typed exception is now.
The error catalogue can be found in S32::Exception. Documentation for compiler writers is in a separate document, and the promised documentation for test authors is in the POD of Test::Util in the "roast" repository.
Now I wait for review of my work by the grant manager (thanks Will) and the grant committee.
I'd like to thank everybody who was involved with the grant.
Sun, 27 May 2012
Exceptions Grant Report for May 2012
Permanent link
It seems quite a long time since I started working on my grant on exceptions, and I until quite recently I felt that I still had quite a long way to go. And then I read the deliverables again, and found that I have actually achieved quite a bit of them already. I also noticed that some of them are quite ambiguously formulated.
Also when I wrote the grant application I had a clever system in the back of my mind that lets you categorize exceptions with different tags. After presenting that idea to the #perl6 channel, they uniformly told me that it was a (bad) reinvention of the existing type system. They were right, of course. So instead exceptions use the "real" type system now, which means that some aspects of the grant application do not make so much sense now.
Let's look at the deliverables in detail:
D1: Specification
S32::Exception contains my work in this area..
Since exceptions use the normal Perl 6 type system, the amount of work I had to do was less than I had expected. I consider it done, in the sense that everything is there that we need to throw typed exceptions and work with them in a meaningful and intuitive way.
There are certainly still open design question in the general space of exceptions (like, how do we indicate that an exception should or should not print its backtrace by default? There are ways to achieve this right now, but it's not as easy as it it should be for the end user). However those open questions are well outside the realm of this grant. I still plan to tackle them in due time.
D2: Error catalog, tests
The error catalog is compiled and in Rakudo's src/core/Exception.pm. It is not comprehensive (ie doesn't cover all possible errors that are thrown from current compilers), but the grant request only required an "initial" catalog. It is certainly enough to demonstrate the feasibility of the design, and to handle many very common cases. I will certainly summarize it in the S32::Exception document.
Tests are in the roast repository. At the time of writing there are 343 tests (Update 2012-06-04: 411 tests), of which Rakudo passes nearly all (the few failures are due to misparses, which cause wrong parse errors to be generated). They cover both the exceptions API and the individual exception types.
D3: Implementation, tests, documentation
The meat of the implementation is done. Not all exceptions thrown from the setting are typed yet, about 30 remain (plus a few for internal errors that don't make sense to improve much). (Update 2012-06-04: all of these 30 errors now throw typed exceptions too). The tests mentioned above already cover several RT tickets where people complained about wrong or less-than-awesome errors. Documentation is still missing, though I have given a walk through the process of adding a new typed exception to Rakudo on IRC, which might serve as a starting point for such documentation.
So in summary, still missing are
- Finish changing text based exceptions to typed exceptions in CORE
- Documenting the error catalog in S32::Exception
- Documentation for compiler writers and test writers
A surprisingly short list :-)
I'd also like to mention that I did several things related to exceptions which were not covered by this grant report:
- greatly improved backtrace printer
- Many exceptions from within the compilation process (such as parse errors, redeclarations etc.) are now typed.
- I enabled typed exceptions thrown from C code, and as a proof of concept I ported all user-visible exceptions in perl6.ops to their intended types.
- Exceptions from within the meta model can now be caught in the "actions" part of the compiler, augmented with line numbers and file name and re-thrown
Wed, 23 May 2012
News in the Rakudo 2012.05 release
Permanent link
The Rakudo Star release 2012.05 comes with many improvements to the compiler. Some people have asked what they mean, so I want to explain some of them here.
The new -I and -M allow manipulation of the library search path and loading of modules, similar to Perl 5.
perl6 -Ilib t/yourtest.t # finds your module under lib/
If you want to manipulate the search path from inside a script or module, you can now use the new lib module, again known from Perl 5.
# file t/yourtest.t; use v6; use lib 't/lib'; # now can load testing modules from t/lib/Yourmodule/Test.pm use Yourmodule::Test; ...
If you look at how lib.pm is
implemented, you'll notice another new feature: the ability to write a
custom EXPORT subroutine -- necessary exactly for things like
lib.pm.
But normal exporting and importing is now handled quite well from Rakudo. You can now mark routines as being exported to certain tag names:
module CGI { sub h1($text) is export(:HTML) { '<h1>' ~ $text ~ '</h1>' } sub param($key) is export { ... }; }
If you want to get only the HTML generating function(s), you can write
use CGI :HTML;
S11 has more details on the exporting and importing mechanism.
You can also import from within a single file by using import
instead of use:
module Greeter { sub hello($who) is export { say "Hello $who"; } } import Greeter; # make sub hello available in the current scope hello('Perl 6 fans');
Thu, 03 May 2012
SQLite support for DBIish
Permanent link
DBIish, the new database interface for Rakudo Perl 6, now has a working SQLite backend. It uses prepared statements and placeholders, and supports standard CRUD operations.
Previously the SQLite driver would randomly report "Malformed UTF-8 string" or segfault, but usually worked pretty well when run under valgrind. The problem turned out to be a mismatch between the caller's and the callee's ideas about memory management.
In particular, parrot's garbage collector would deallocate strings passed to sqlite3_bind_text after the call was done, but sqlite wants such values to stay around until the next call to sqlite3_step in the very least.
Fixing this mismatch was enabled by this patch, which lets you mark strings as explicitly managed. Such strings keep their marshalled C string equivalent around until they are garbage-collected themselves. So now the sqlite driver keeps a copy of the strings as long as necessary, and the SQLite tests pass reliably.
Currently it still needs the cstr branches in the nqp and
zavolaj repositories, but they will be merged soon -- certainly before the May
release of Rakudo.
Sat, 28 Apr 2012
Meet DBIish, a Perl 6 Database Interface
Permanent link
In the aftermath of the Oslo Perl 6 hackathon 2012, I have decided to fork and rename MiniDBI. MiniDBI is intended as a compatible port of Perl 5's excellent DBI module to Perl 6. While working on the MiniDBI backends, I noticed that I became more and more unhappy with that. Perl 6 is sufficiently different from Perl 5 to warrant different design decisions in the database interface layer.
Meet DBIish. It started with MiniDBI's code base, but has some substantial deviations from MiniDBI:
- Connection information is passed by named arguments to the driver (instead of a single DSN string)
- Different naming of several methods. There's not much point in having
both
fetchrow_arrayandfetchrow_arrayrefin Rakudo.fetchrowsimply returns an array or a list, and the caller decides what to do with it. - Backends only need to implement
fetchrowandcolumn_names, and get all the other fetching methods (likefetchrow-hash,fetchall-hash) for free. - Error handling from DB connection and statement handle are unified into a single row
The latter two changes brought quite a reduction in backend code size.
My plans for the future include experimenting with different names and maybe totally different APIs. When a language has lazy lists, one can simply return all rows lazily, instead of encouraging the user to fetch the rows one by one.
Currently the Postgresql and mysql backends support basic CRUD operations, Postgresql with proper prepared statements and placeholders. An SQLite backend is under way, but still needs better support from our native call interface.
Mon, 23 Apr 2012
Perl 6 Hackathon in Oslo: Report From The Second Day
Permanent link
Second day of the Perl 6 Patterns Hackathon. My plans to get the rest of placeholders and prepared statements working in the Postgresql backend for MiniDBI succeed about 10 minutes after midnight. I just wanted to give them a very quick try before going to bed, and was successful. Then I went to sleep.
It was night, and it was morning. Second day.
Next I wrote an SQLite backend for MiniDBI. It blocked on missing features in our native call infrastructure, on which arnsholt worked in parallel. So I haven't had a chance to try the SQLite backend yet. It probably requires some substantial amount of work before it will run, but at least it compiles.
I also investigated prepared statements and placeholders for the mysql backend. This is much less straight forward, because it requires filling in members of structs, not just function calls. This by itself wouldn't be much a problem, our native call infrastructure supports that. The problem is that it's a struct of mixed "private" and "public" members, so modelling the structure in Perl 6 requires modeling private data of the mysql client library. While possible, I don't find it desirable, because it is rather fragile.
Another notable event was the hacking dojo, where about 8 of us collaborated to write a roman numeral conversion, using pair programming, and fixed cycles of first writing a failing test, then getting it to run in the simplest possible way, and finally refactoring it. It was quite an interesting and fun experience.
I spent much of the rest of the hackathon discussing things. For example Patrick Michaud gave a quick walk through of how lists and related types are implemented and iterated in Rakudo.
In the evening we had very tasty Vietnamese food, and generally a good time.
Again it was a very productive and enjoyable day, and I'm very grateful for being invited to the Hackathon.
Sat, 21 Apr 2012
Perl 6 Hackathon in Oslo: Report From The First Day
Permanent link
Yesterday I arrived in the beautiful city of Oslo to attend the Perl 6 Patterns Hackathon. Yesterday we visited a pub, had great discussions, food and beverages, and generally a very good time.
Today we met at 10 am, and got straight to hacking. We are located in an office in the 6th floor of a big building, with a nice view over the center of town, harbor, and even the Holmenkollen.
I worked on the backtrace printer, which in alarmingly many cases reported
Error while creating error string: Method 'message' not found for
invocant of class 'Any', which wasn't too helpful.
It turns out there were actually two causes. One was a subtle error in the
backtrace printer that was triggered by stricter
implementation of the specification, which was easy to find. The
second bug was harder to find, considering that you don't get easily get
backtraces from errors within the backtrace printer. In the end it was the
usage of a code object in boolean context, which turned out to be harmful.
Because regexes are also code objects, and in boolean context they search for
the outer $_ variable and try to match the regex against it.
Which failed. Hard to find, but easy to fix.
My second big project today was database connectivity. Part of it was pestering Jonathan to fix the issues that arose from module precompilation mixed with calling C modules, and testing all the iterations he produced. I'm happy to report that it now works fine, which speeds up development quite a bit.
I also fixed the postgres driver. The root cause for the failing tests turned out to be rather simple too (a missing initialization), so simple that it's embarrassing how long it took me to find out. On the plus side I improved the code quite a bit in passing.
So now all tests in MiniDBI pass, which is a nice milestone, and an indication that we need more tests.
Tomorrow I plan to change the postgres driver to use proper prepared statments.
But the real value of such hackathon comes from interacting with the other hackers. I'm very happy about lots of discussions with other core hackers, as well as feedback and patches from new users and hackers.
At this occasion I'd also like to thank the organizers, Salve J. Nilsen, Karl Rune Nilsen and Jan Ingvoldstad. It has been a great event so far, both fun and productive. You are doing a great service to the Perl 6 community, and to the hackers you have invited.
Thu, 12 Apr 2012
Rakudo Hack: Dynamic Export Lists
Permanent link
Rakudo's meta programming capabilities are very good when it comes to objects, classes and methods. But sometimes people want to generate subroutines on the fly and use them, and can't seem to find a way to do it.
The problem is that subroutines are usually stored (and looked up from) in
the lexical pad (ie the same as my-variables), and those lexpads
are immutable at run time.
Today I found a solution that lets you dynamically install subroutines with
a computed name into a module, and you can then use that module
from elsewhere, and have all the generated subroutines available.
module A { BEGIN { my $name = 'foo'; my $x = sub { say 'OH HAI from &foo' } but role { method name { $name } }; trait_mod:<is>(:export, $x); } }
Inside the module first we need a BEGIN block, so that the
is export trait will run while the module is being compiled, and
thus knows which module to associate the subroutine to.
Next comes the actual code object that is to be installed. Since the
export trait inspects the name of the subroutine, we need to give
it one. Doing that dynamically can be done by overriding the name
method, here by mixing in a role with such a method into the code object.
Finally comes the part where the export trait is applied. The code here uses knowledge of the calling conventions that hide behind a trait.
A different script can then write
use A; foo();
And access the dynamically exported sub just like any other.
In future there will hopefully be much nicer APIs for this kind of fiddling, but for now I'm glad that a workaround has been found.
Tue, 10 Apr 2012
Perl 6 Hackathon in Oslo: Be Prepared!
Permanent link
The Oslo Perl Mongers invite to the Perl 6 Patterns Hackathon in Oslo. I have previously suggested that we hack on database connectivity, and so far only got positive feedback. If you want to help, here is what you can do to be prepared:
- Get a github account
- Build and install Rakudo
- Build and install zavolaj/NativeCall
- download MiniDBI
- install and prepare databases to talk to
To hack efficiently on those projects, and to benefit from last-minute fixes, you should obtain Rakudo, NativeCall and MiniDBI from their git source repositories -- that last release is already outdated.
Here are the instructions in detail. If at any point you run into problems, feel free to ask on the #perl6 IRC channel or the perl6-users@perl.org mailing list.
Get a Github account
All the interesting Perl 6 code lives in git repositories on github. If you don't have an account already, sign up -- it's free.
Build and install Rakudo
This step is described well on the Rakudo homepage. Please follow the instruction in section "Building the compiler from source".
For the following steps it is important that you have a fresh
perl6 executable file in your $PATH. If you have downloaded
rakudo to /home/you/p6/rakudo/, you can run the command
PATH=$PATH:/home/you/p6/rakudo/install/bin
(and put it in your ~/.bashrc file if you want it permanently available, not just in this shell).
Build and install zavolaj/NativeCall
NativeCall.pm is the high-level interface for calling C functions from Perl 6 code. Install it:
$ git clone git://github.com/jnthn/zavolaj.git $ cd zavolaj $ cp lib/NativeCall.pm6 ~/.perl6/lib/
If you download and install ufo, you can use it create a
Makefile for zavolaj. Then you can also run make test. On Linux it might not find the
test libraries (which is mostly harmless, because you usually call libraries
that are installed into your operating system, like those from mysql or
postgres). In this case you should run LD_LIBRARY_PATH=. make
test instead.
Download MiniDBI
That's not hard at all:
$ git clone git://github.com/mberends/MiniDBI.git
Install and Prepare Databases
So far, MiniDBI has (somewhat limited) support for mysql and postgres. Since it is always easiest to start from (at least somewhat) working code, I strongly recommend that you install at least one of those database engines.
Most modern Linux systems allow an easy installation via the package manager, and there are installers available for other operating systems. Be sure to also install the headers or development files if they come as extra packages.
Mysql
As mysql root user, run these statements:
CREATE DATABASE zavolaj; CREATE USER 'testuser'@'localhost' IDENTIFIED BY 'testpass'; GRANT SELECT ON mysql.* TO 'testuser'@'localhost'; GRANT CREATE ON zavolaj.* TO 'testuser'@'localhost'; GRANT DROP ON zavolaj.* TO 'testuser'@'localhost'; GRANT INSERT ON zavolaj.* TO 'testuser'@'localhost'; GRANT DELETE ON zavolaj.* TO 'testuser'@'localhost'; GRANT LOCK TABLES ON zavolaj.* TO 'testuser'@'localhost'; GRANT SELECT ON zavolaj.* TO 'testuser'@'localhost';
Postgres
Launch psql as the postgres user and run these
statements:
CREATE DATABASE zavolaj; CREATE ROLE testuser LOGIN PASSWORD 'testpass'; GRANT ALL PRIVILEGES ON DATABASE zavolaj TO testuser;
You should now be able to connect with:
psql --host=localhost --dbname=zavolaj --username=testuser --password
(psql will ask you for the password. Enter testpass).
Other Databases
If you want to work on a backend for another database, it helps to have that database installed. Sqlite is an obvious choice (easy to install, zero setup), but of course there are other free database too, like firebird.
Project ideas
There is a lot of stuff to do. What follows is only a loose, incomplete collection of ideas.
- Fix the postgres backend to actually pass its tests
- Both mysql and postgres backends don't implement placeholders properly; change them (or one of them) to pass the placeholder values out of band.
- Write an sqlite backend
- Currently the user builds a DSN ("data source name") string out of the driver name, database name, db host name and so on, and then the driver parses it again. One could change that to pass all the information as named parameters instead.
- Improve test coverage. For example test that numbers round-trip with the correct types.
- Write a small application that uses a database. That's the best way to see if MiniDBI and the backends work.
Tue, 20 Mar 2012
Upcoming Perl 6 Hackathon in Oslo, Norway
Permanent link
The Oslo Perl Mongers are inviting to the Perl 6 Patterns Hackathon in Oslo in one month, and I very much look forward to being there.
Hackathons can be quite fun and productive if many programmers focus on the same goal. So to make the hackathon a success, I'm willing to work on whatever we decide to set as our goal(s).
One topic that is dear to me, and that is approachable by a horde of programmers (and guided by one or two Rakudo core hackers) is bringing database access into a usable state.
With muchly improved support for calling C functions and NativeCall.pm we should have enough infrastructure for access mysql, postgres and SQLite databases. MiniDBI aims to provide some basic convenience, but currently only the mysql driver partially works.
I believe that with concentrated effort, MiniDBI and the rest of the infrastructure can be improved to the point that it is usable, and other modules can start to rely on it. Databases usable in Perl 6, doesn't that sound good?
I'll see what kind of feedback I get on this idea, and if it's positive, I'll follow up with instructions on how to install the prerequisites for hacking on MiniDBI and its drivers.
Tue, 28 Feb 2012
Current State of Exceptions in Rakudo and Perl 6
Permanent link
It's been a while since my last update on my grant work on exceptions for Perl 6 and Rakudo, and I can report lots of progress.
The work on Rakudo's exception system made me realize that we conflated two concepts in the base exception type: on the one hand the infrastructure for reporting errors and backtraces, and on the other hand holding some sort of error message as an attribute.
As a result, we now have a base class called Exception from
which all exception types must inherit. When a non-Exception
object is passed to die(), it is wrapped in an object of class
X::AdHoc. Other error classes can decide to generate the error
message without having an attribute for it (for example hard-coded in a
method).
Typed exceptions are now thrown not only from the setting, but also from the compiler itself, namely the grammar and the action methods. In fact the majority of errors from these two parts of the compiler are now handled with dedicated exception types.
The most user-visible change is a new and improved backtrace printer, which produces usually much shorter and more readable backtraces. The old one is still available on demand. Consider the program
sub f { g() for 1..10; } sub g { die 'OH NOEZ' } f;
The old backtrace printer produced:
OH NOEZ in sub g at /home/moritz/p6/rakudo/ex.pl:4 in block <anon> at /home/moritz/p6/rakudo/ex.pl:2 in method reify at src/gen/CORE.setting:4471 in method reify at src/gen/CORE.setting:4376 in method reify at src/gen/CORE.setting:4376 in method gimme at src/gen/CORE.setting:4740 in method eager at src/gen/CORE.setting:4715 in method eager at src/gen/CORE.setting:1028 in sub eager at src/gen/CORE.setting:5000 in sub f at /home/moritz/p6/rakudo/ex.pl:2 in block <anon> at /home/moritz/p6/rakudo/ex.pl:5 in <anon> at /home/moritz/p6/rakudo/ex.pl:1
Where the eager, gimme and reify methods come from the 'for' lop, which is
compiled to the equivalent of eager (1..10).map: { g() }.
The new backtrace printer produces
OH NOEZ in sub g at ex.pl:4 in sub f at ex.pl:2 in block <anon> at ex.pl:5
It is also a special pleasure to report that after a walk through a change to throw a typed exception, we've received a pull request by a new developer which also changes an exception from X::AdHoc to a dedicated type.
Sat, 18 Feb 2012
Results from the Prisoner's Dilemma Challenge
Permanent link
The Iterated Prisoner's Dilemma Challenge is now closed; several interesting solutions have been submitted.
Of the basic strategies, tit-for-tat (doing what the opponent did the last time, starting off with cooperating) is usually the strongest. Since the random strategy is, well, random, the results fluctuate a bit.
Most submitted strategies are a variation on tit-for-tat, modified in some way or another to make it stronger. All submissions contained a strategy that is stronger than tit-for-tat when tested against the basic strategies only, though the interaction with other new strategies made some of them come out weaker than tit-for-tat.
Submitted Strategies
Without any further ado, here are the strategies and a few comments on them.
Turn the Other Cheek
## Dean Serenevy; received on 2012-02-07 %strategies<turn-other-cheek-no-deal-with-devil-once-bit-twice-shy-variety-is-the-spice-o-life> = sub (:@mine, :@theirs, *%) { my ($bitten, $shy, $they-coop) = (0, 0, False); for @mine Z @theirs -> $me, $them { if $them { $they-coop = True; } if $me and !$them { $bitten++; $shy = 0; } if !$me { $shy++ } } return True if 0 == $bitten; # Cooperate if we have never been bitten return True if 1 == $bitten and 0 == $shy; # Turn the other cheek once return False unless $they-coop; # Screw you too! return $shy >= (2 ** ($bitten-1)).rand # Once-bitten rand() shy };
Inevitable Betrayal
## Andrew Egeler, received 2012-02-09 %strategies<inevitable-betrayal> = &inevitable-betrayal; sub inevitable-betrayal (:@theirs, :$total, *%) { +@theirs < ($total-1) ?? @theirs[*-1] // True !! False } %strategies<evil-inevitable-betrayal> = &evil-inevitable-betrayal; sub evil-inevitable-betrayal (:@theirs, :$total, *%) { +@theirs < ($total-1) ?? @theirs[*-1] // False !! False }
These are variations on tit-for-tat and evil-tit-for-tat which always defect in the last round, because then the opponent can't retaliate anymore.
In a typical Iterated Prisoner's Dilemma contest, strategies don't know how many rounds are being played, just to avoid this behavior.
Tit for D'oh and Watch for Random
## Solomon Foster, receievd 2012-02-10 %strategies<tit-for-doh> = -> :@theirs, :$total, *% { @theirs < $total - 1 ?? (@theirs[*-1] // True) !! False } %strategies<watch-for-random> = -> :@theirs, *% { @theirs > 10 && @theirs.grep(* == False) > 5 ?? False !! (@theirs[*-1] // True) };
tit-for-doh is the same as inevitable-betrayal. watch-for-random defects forever once the opponent has defected too often.
Me
## Audrey Tang, received 2012-02-17 %strategies<me> = -> :@theirs, *% { my role Me {}; (@theirs[*-1] // Me).does(Me) but Me };
This strategy uses a mixin in its returned boolean values to find out when
it plays against itself, or against a strategy that copies its values from
@theirs (ie tit-for-tat derivatives), in which case it cooperates.
This games the system, though doesn't explicitly violates the stated rules.
Audrey also deserves two dishonorable mentions for two solutions that game the test harness or the other strategies by exploiting the technically imperfect sandboxing:
au => -> :@theirs, *% { use MONKEY_TYPING; my role TRUE {}; augment class Bool { method Stringy(Bool:D:) { self.^does(TRUE) ?? 'True' !! 'False' } } False but TRUE; }, amnesia => -> :@mine, :@theirs, *% { my role Uh {}; my $rv = (@theirs[*-1] // Uh).does(Uh) but Uh; @mine = @theirs = (); $rv; },
Those two strategies did not compete in the tournament
Lenient in the Beginning, Then Strict
I've written my own two strategies before the tournament started. Here is the original, I've only changed the signatures to run under current Niecza:
# a tit for tat, but a bit more friendly at the beginning # to avoid hacking on forever on evil-tit-for-tat, # but be very stringent when the other one defects too often sub moritz-ctft(:@theirs, :$total, *%) { return True if @theirs < 3; return False if @theirs.grep(*.not).elems > ($total / 10); @theirs[*-1]; }; %strategies<moritz-ctft> = &moritz-ctft; # the evil clone... sub moritz-ectft(:@theirs, :$total, *%) { return True if @theirs < 3; return False if @theirs.grep(*.not).elems > ($total / 10); # did you believe in happy ends? return False if @theirs + 1 == $total; @theirs[*-1]; }; %strategies<moritz-ectft> = &moritz-ectft;
Results
The results vary quite a bit between runs, mostly because of the random strategy.
Here is the output from a sample run. Please don't use this for determining the "winner", because it is just a random sample with no statistical significance.
SUMMARY 2588 moritz-ectft 2577 me 2560 moritz-ctft 2491 inevitable-betrayal 2483 tit-for-tat 2480 tit-for-doh 2399 turn-other-cheek-no-deal-with-devil-once-bit-twice-shy-variety-is-the-spice-o-life 2319 watch-for-random 2272 good 1876 evil-inevitable-betrayal 1862 evil-tit-for-tat 1538 random 1145 bad
You see, inevitable-betrayal and tit-for-doh are exactly the same strategy, but the random fluctuations place them on different sides of tit-for-tat. Which is why I won't declare a winner at all, there is simply no fair way to determine one.
At first I was surprised how well the me strategy performed. But then I noticed that with the given game harness, a strategy fighting against itself counts double (once for the first copy, once for the second copy). With only 13 strategies participating, and such close results, harmonizing perfectly with yourself gives you a critical advantage.
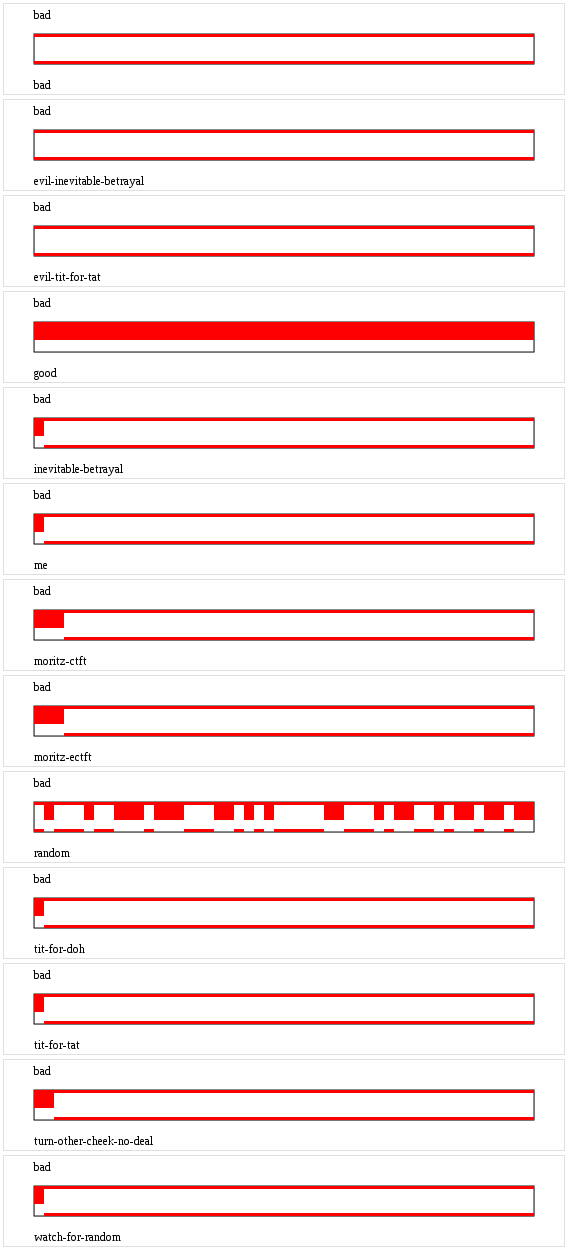
Visualizations
For each strategy you can find an image that shows how it worked with or against another strategy. Green means cooperate, red means defect, and the height of the bar is proportional to the resulting score.
- bad
- evil-inevitable-betrayal
- evil-tit-for-tat
- good
- inevitable-betrayal
- me
- moritz-ctft
- moritz-ectft
- random
- tit-for-doh
- tit-for-tat
- turn-the-other-cheek-no-deal...
- watch-for-random
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Trying to Be Fair
In an attempt to reduce the impact of the random strategy, I've changed it to use the same random sequence against each player (and of course against itself, which totally skews that particular result).
Again the rankings vary between different runs of the same program, but now at least same strategies produce mostly the same result (turn-the-other-cheek also has a random component). An example output from such a run is
SUMMARY 2558 moritz-ectft 2543 moritz-ctft 2532 me 2457 inevitable-betrayal 2457 tit-for-doh 2445 tit-for-tat 2387 turn-other-cheek-no-deal-with-devil-once-bit-twice-shy-variety-is-the-spice-o-life 2314 watch-for-random 2248 good 1856 evil-inevitable-betrayal 1844 evil-tit-for-tat 1359 random 1100 bad
TL;DR
It was a lot of fun! Thanks to everybody who submitted a strategy.
Tue, 07 Feb 2012
Mini-Challenge: Write Your Prisoner's Dilemma Strategy
Permanent link
Here is a small task we considered for the Perl 6 Coding Contest, but not chose to not pursue. But it's a nice little challenge for your leisure time.
In the Prisoner's Dilemma, two suspected criminals can choose to not betray each other (which we call "cooperate"), or betraying the other ("defecting"). If only one suspect betrays the other, the traitor gets released and the betrayed one gets a long sentence; if both betray each other, both get a rather long sentence. If both cooperate, both get rather short sentences.
It becomes more interesting when the dilemma is repeated multiple times. Now instead of prison sentences the contestants are assigned scores, which add up over multiple rounds.
I challenge you to write one or two strategies for the iterated prisoner's dilemma, and send them to moritz.lenz@gmail.com no later than Friday February 17.
You'll find some basic strategies and a harness here. It runs on both newest Rakudo and Niecza.
The scoring is as follows, where True means cooperate and
False means defect:
my %scoring =
'True True' => [4, 4],
'True False' => [0, 6],
'False True' => [6, 0],
'False False' => [1, 1],
Your strategy should be a subroutine or block that accepts the named
parameters mine and theirs, which are lists
of previous decisions of your own algorithm and of its opponents, and
total, which is the number of laps to be played. It should
return True if it wishes to cooperate, and False to
defect.
Here is an example strategy that starts off with cooperating, and then randomly chooses a previous reaction of the current opponent:
sub example-strategy(:@theirs, *%) {
@theirs.roll // True;
}
Your strategy or strategies will play against each other and against the example strategies in the gist above. It is not allowed to submit strategies that commit suicide to actively support another strategy.
I too have written two strategies that will take participate in the contest. Here is the checksum to convince you I won't alter the strategies in response to the submissions:
6d4ba99b66e4963a658c8dcfc72922dd0f74e0ad prisoner-moritz.pl